一、运算符
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| And | 同时满足两个条件的值 |
| Or | 满足其中一个条件的值 |
| Not | 满足不包含该条件的值 |
| is null | 空值判断 |
| between and | 在某个范围内 |
| LIKE | 模糊查询( % 表示多个字值,_下划线表示一个字符; ) |
| IN | 指定针对某个列的多个可能值 |
1 | CREATE DATABASE IF NOT EXISTS RUNOOB DEFAULT CHARSET utf8 COLLATE utf8_general_ci; |
数据库的校验规则
utf8_bin:将字符串中的每一个字符用二进制数据存储,大小写敏感utf8_genera_ci:大小写不敏感(ci:case insensitive)utf8_general_cs:大小写敏感(cs:case sensitive)1 | CREATE TABLE IF NOT EXISTS `runoob_tbl`( |
ENGINE=InnoDB:使用innodb引擎1 | drop database if exists db_name; |
1 | drop table if exists table_name; |
koa 提供了从上下文直接读取、写入 cookie 的方法
1 | ctx.cookies.get(name, [options]) // 读取上下文请求中的 cookie |
options 的配置如下:
httpOnly:是否只有服务器可以去到 cookie,默认为 true
overwrite:是否允许重写
1 | const Koa = require('koa'); |
ctx.request是context经过封装的请求对象,ctx.req是context提供的node.js原生HTTP请求对象。
同理ctx.response是context经过封装的响应对象,ctx.res是context提供的node.js原生HTTP请求对象。
在koa中,获取GET请求数据源头是koa中request对象中的query方法或querystring方法。query返回是格式化好的参数对象,querystring返回的是请求字符串。
1 | const Koa = require('koa') |
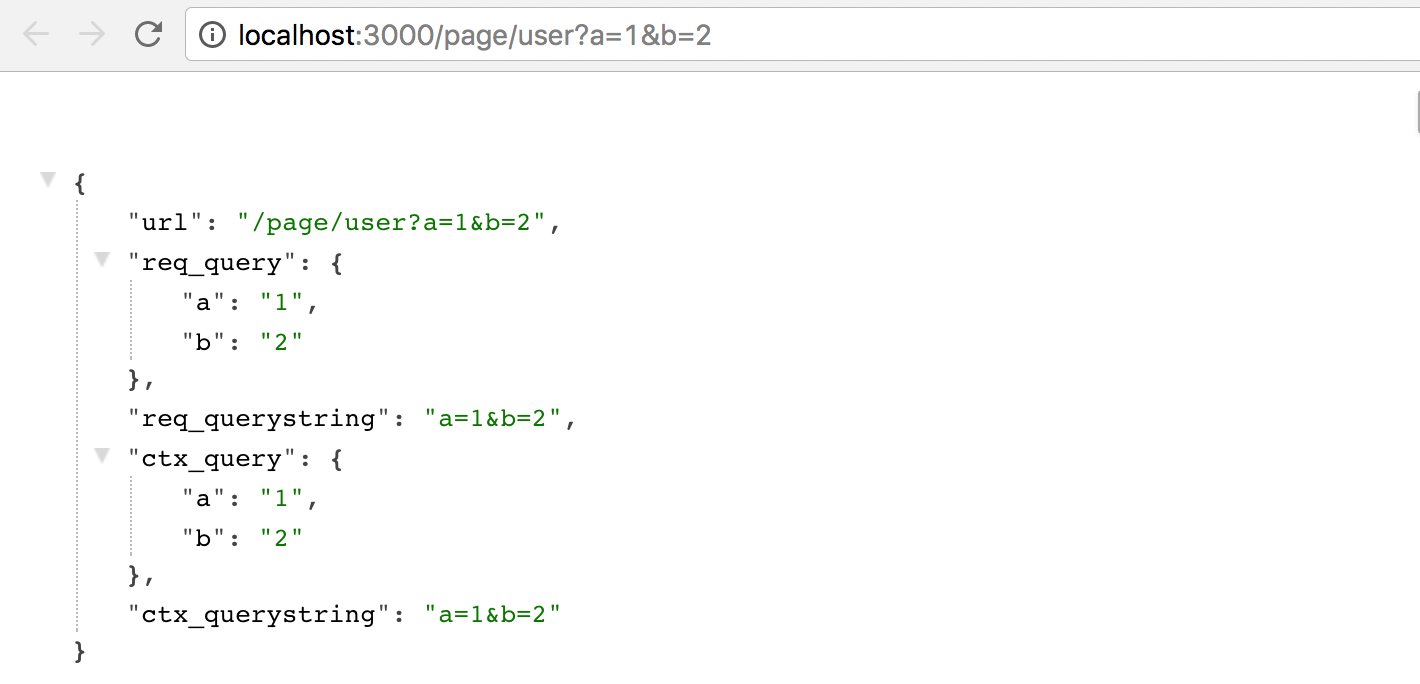
Koa2通过app.use()把很多async函数组成一个处理链,每个async函数都可以做一些自己的事情,然后用await next()来调用下一个async函数。我们把每个async函数称为middleware。
1 | // 在koa2中,我们导入的是一个class,因此用大写的Koa表示: |
koa约定了一个中间件的存储空间ctx.state,通过这个state可以共享一些的数据。
1 | const mysql = require('mysql') |
一般情况下操作数据库是很复杂的读写过程,不只是一个会话,如果直接用会话操作,就需要每次会话都要配置连接参数。所以这时候就需要连接池管理会话。
1 | const mysql = require('mysql') |
1 | const Koa = require('koa') |
1 | var a = {n:1}; |
下面来分析下这段简单代码的工作步骤,从而进一步理解js引用类型“赋值”的工作方式。首先是:
1 | var a = {n:1}; |
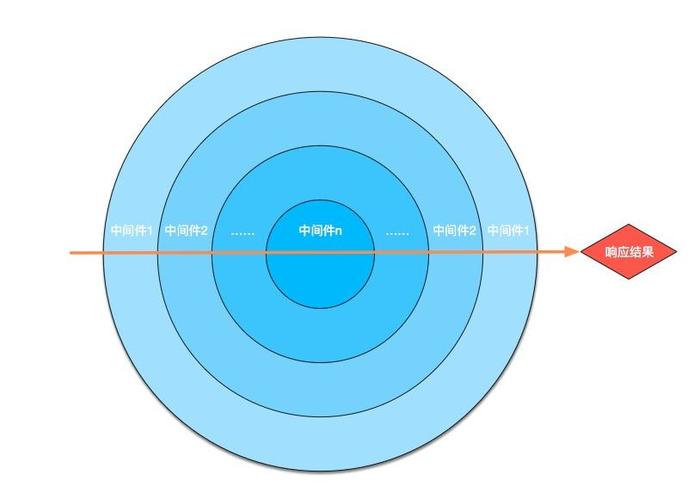
在这里a指向了一个对象{n:1}(我们姑且称它为对象A),b指向了a所指向的对象,也就是说,在这时候a和b都是指向对象A的。这一步很好理解,接着继续看下一行非常重要的代码:
1 | a.x = a = {n:2}; |
我们知道js的赋值运算顺序永远都是从右往左的,不过由于“.”是优先级最高的运算符,所以这行代码先解析了a.x。这时候发生了这个事情——a指向的对象{n:1}新增了属性x(虽然这个x是undefined的):

从图上可以看到,由于b跟a一样是指向对象A的,要表示A的x属性除了用a.x,自然也可以使用b.x来表示了。
接着,依循“从右往左”的赋值运算顺序先执行 a={n:2} ,这时候,a指向的对象发生了改变,变成了新对象{n:2}(我们称为对象B):
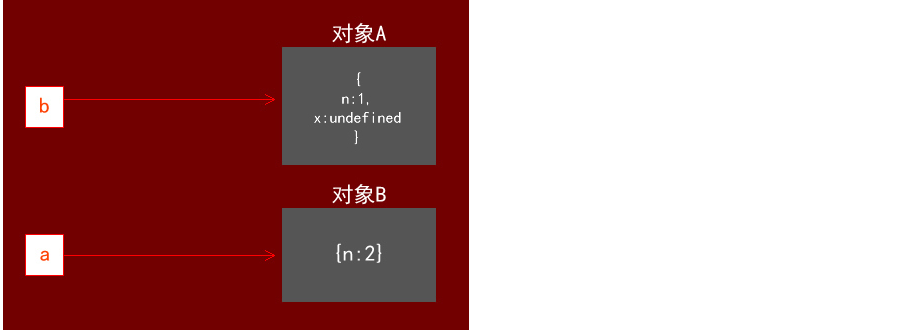
接着继续执行
1 | a.x = a; |
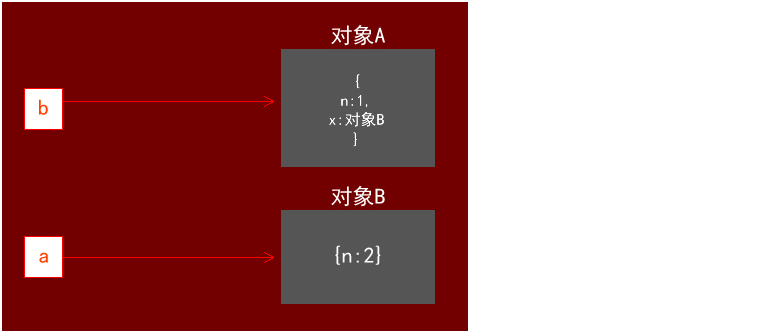
很多人会认为这里是“对象B也新增了一个属性x,并指向对象B自己”。但实际上并非如此,由于( . 运算符最先计算)一开始js已经先计算了a.x,便已经解析了这个a.x是对象A的x,所以在同一条公式的情况下再回来给a.x赋值,也不会重新解析这个a.x为对象B的x。所以 a.x=a 应理解为对象A的属性x指向了对象B:
若不配置,默认值为当前目录,webpack设置 context 默认值代码:
1 | this.set("context", process.cwd()); |
process.cwd()即webpack运行所在的目录(等同package.json所在目录)。
context 应该配置为绝对路径,假如入口起点为src/main.js,则可以配置:
1 | { |
此时 entry 不能再配置为’./src/main.js’,因为 webpack 会相对于 context 配置的 src 目录区查找入口起点(main.js),而 main.js 就在此目录下,所以应当将 entry 配置为当前目录(./)。
context 有什么实际作用?官方文档的解释是使得你的配置独立于工程目录 「This makes your configuration independent from CWD (current working directory)」。怎么理解?举个例子,在分离开发生产配置文件时候,一般把 webpack.config 放到 build 文件夹下,此时 entry 却不用考虑相对于 build 目录来配置,仍然要相对于 context 来配置,这也就是所谓的独立于工程目录。
需要注意的是,output 的配置项和 context 没有关系,但是有些插件的配置项和 context 有关,后面会说明。
打包文件输出的目录,建议配置为绝对路径(相对路径不会报错),默认值和 context 的默认值一样,都是process.cwd()。除了常规的配置方式,还可以在 path 中用使用 [hash] 模板,比如配置:
1 | output: { |
这里的 hash 值是编译过程的 hash,如果被打包进来的内容改变了,那么 hash 值也会发生改变。这个可以用于版本回滚。为方便做持续集成等,你也可以配置:
1 | output: { |