SimHash
SimHash是Google处理海量网页采用的文本相似判定方法。算法的主要思想是降维,将高维的特征向量映射成一个f-bit的指纹(fingerprint),通过比较两篇文章的f-bit指纹的Hamming Distance来确定文章是否重复或者高度近似。
具体的simhash过程如下:
- 首先基于传统的
IR方法,将文章转换为一组加权的特征值构成的向量。 - 初始化一个
f维的向量V,其中每一个元素初始值为0。 - 对于文章的特征向量集中的每一个特征,做如下计算: 利用传统的
hash算法映射到一个f-bit的签名。对于这个f- bit的签名,如果签名的第i位上为1,则对向量V中第i维加上这个特征的权值,否则对向量的第i维减去该特征的权值。 - 对整个
特征向量集合迭代上述运算后,根据向量V中每一维向量的符号来确定生成的f-bit指纹的值,如果向量V的第i维为正数,则生成f-bit指纹的第i维为1,否则为0。
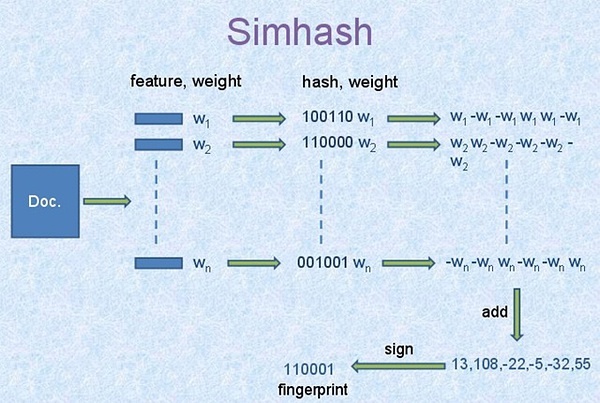
SimHash为Google处理海量网页的采用的文本相似判定方法。该方法的主要目的是降维,即将高维的特征向量映射成f-bit的指纹,通过比较两篇文档指纹的汉明距离来表征文档重复或相似性。
汉明距离-Hamming Distance
汉明距离用来计算两个向量的相似度,即通过比较向量每一位是否相同,若不同则汉明距离加1。
这样得到汉明距离。向量相似度越高,对应的汉明距离越小。如10001001和10110001有3位不同。
与余弦相似性算法的区别
余弦相似性算法:通过对两个文本分词,TF-IDF算法向量化,对比两者的余弦夹角,夹角越小相似度越高,但由于有可能一个文章的特征向量词特别多导致整个向量维度很高,使得计算的代价太大不适合大数据量的计算。
余弦相似性算法适合于短文本SimHash算法适合于长文本,并且能应用于大数据环境中